We implement complex software architectures
based upon the most ground-breaking technologies
available on the market.








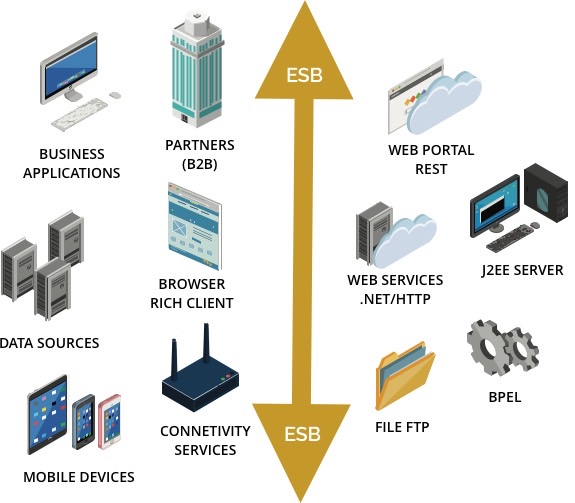
We have designed and implemented software architectures to integrate the IT systems of the main telecommunication companies in Italy, some big banking institutions, as well as in the ITS industry (Intelligent Transport Systems).
We hold a very high know-how and expertise about EAI and ESB platforms. We work with the main ESB and service buses available on the market (Tibco, Mule ESB, IBM, Oracle).